近日,太阳成集团tyc122ccvip与计算中心、计算机学院、元培学院的联合团队,在 arXiv 预印本平台发布了最新成果 SUPERChem。该研究针对当前化学领域基准测试中存在的题目难度有限、多模态与推理过程评估缺失等不足,系统构建了一个专注于评估大语言模型多模态化学推理能力的新型基准,旨在推动更全面、深入的化学智能评测体系的发展。
——背景——
2025年,随着开源推理模型 DeepSeek-R1 推出,LLM 在“深度思考”范式下飞速发展。LLM 在自然科学领域的应用已从简单问答转向复杂科学推理。然而,现有通用科学基准测试已趋于饱和,前沿模型在 GPQA Diamond 上的分数也已经超过90分;化学领域专用基准往往关注基础化学能力、化学信息学任务等,缺乏对化学领域深度推理能力的考察。
从基础教育、化学奥林匹克竞赛到大学乃至研究生阶段,化学学习始终强调知识的综合运用与多步推理。这一学习过程能有效考察复杂化学问题的解决能力,成为评估化学推理水平的理想场景。相应地,要设计出适用于此类评估的高质量题目,必须将抽象概念与具体情境深度融合,构建出层层递进的推理链条,这对出题者的专业素养提出了极高要求。太阳成集团tyc122ccvip拥有国内水平顶尖的本科生和研究生群体,他们兼具扎实的学科功底与丰富的解题、命题经验,能够对已有题目素材进行准确评估与合理优化。
122cc太阳成集团研究团队充分发挥这一独特优势,召集大量优秀学生共同构建了 SUPERChem 基准测试,填补了现有评估体系在多模态化学深度推理方面的空白。
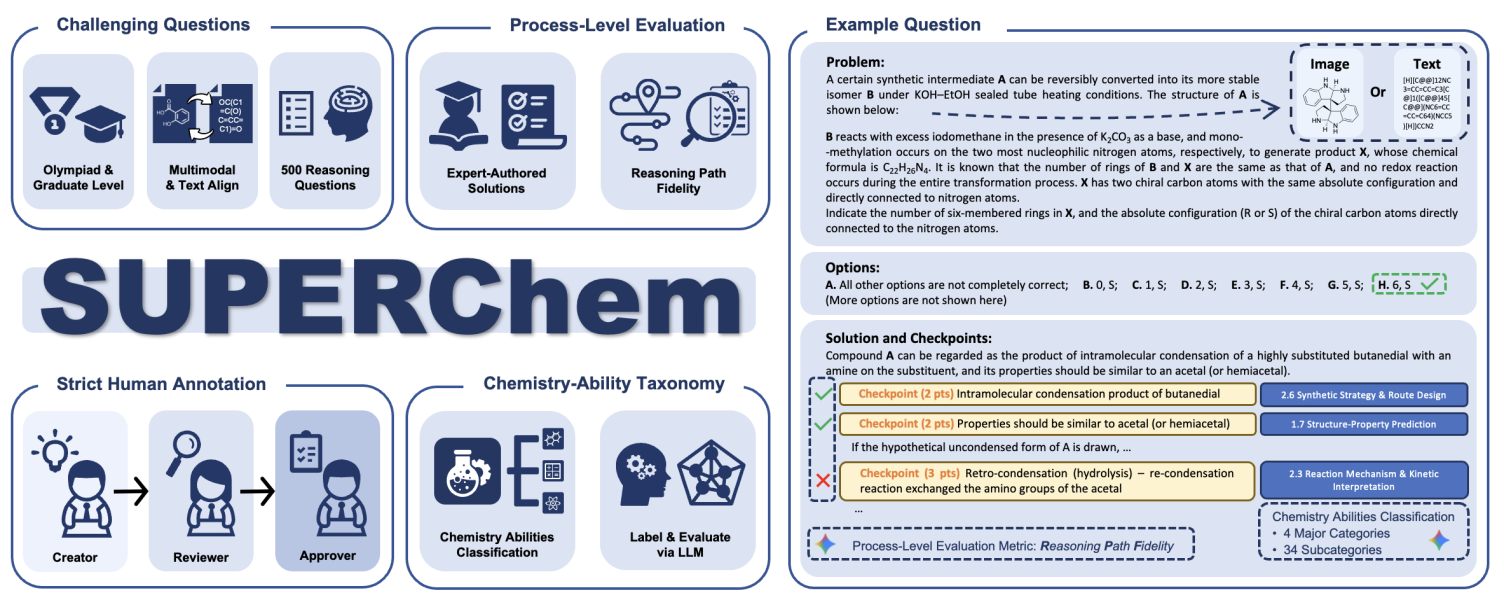
图1. SUPERChem 总览与例题
——数据构建——
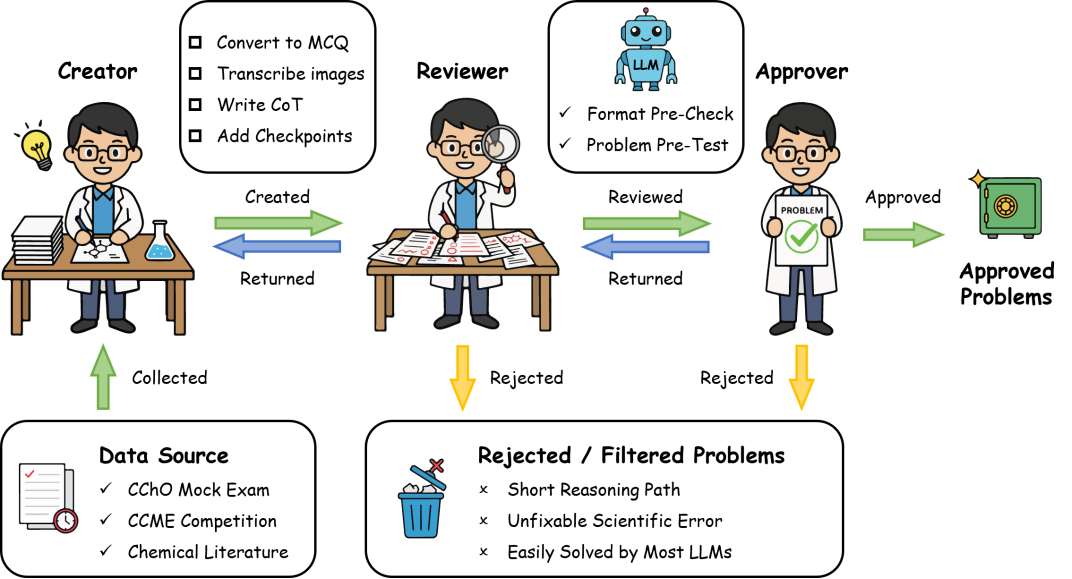
图2. SUPERChem 题库的三阶段审核流程
SUPERChem 题库由近百名122cc太阳成集团化学专业的师生共同构建,涵盖题目编写、解析撰写以及严格的三阶段审核流程。题目来源于高难度非公开化学竞赛模拟题、北大化院内部试题及专业文献改编,并采用严谨的防泄漏选择题设计,避免 LLM 作答时依赖自身记忆或从选项逆推取巧。
化学学科的学习和研究需要使用多样的图像,例如分子结构、晶体结构、光谱等,表达丰富的信息。针对化学的多模态特性,SUPERChem 同步提供了图文交错与纯文本两个版本的对齐数据集。这一设计不仅能深入评估 LLM 的跨模态化学推理能力,还为系统探究视觉信息对推理过程的影响提供了基础。
目前,SUPERChem 先期发布500 道专家级精选题目,覆盖结构与性质、化学反应与合成、化学原理与计算、实验设计与分析四大化学核心领域。为了细粒度地评估 LLM 的思考过程, SUPERChem 创新性地引入推理路径一致性( Reasoning Path Fidelity, RPF )指标。研究团队为每道题目撰写了包含关键检查点( Checkpoints )的详细解析,通过自动化评估 LLM 生成的思维链与解析的一致性,从而有效区分模型是真正“理解”化学原理,还是仅凭启发式猜测偶然答对。
——评测结果——
1. 前沿模型接近低年级本科生水平,不同模型推理一致性存在差异
评测结果显示,SUPERChem 具有较高的题目难度和区分度。在122cc太阳成集团化学专业低年级本科生的闭卷测试中,人类基线准确率为 40.3%。
表1. 前沿模型在SUPERChem上的表现
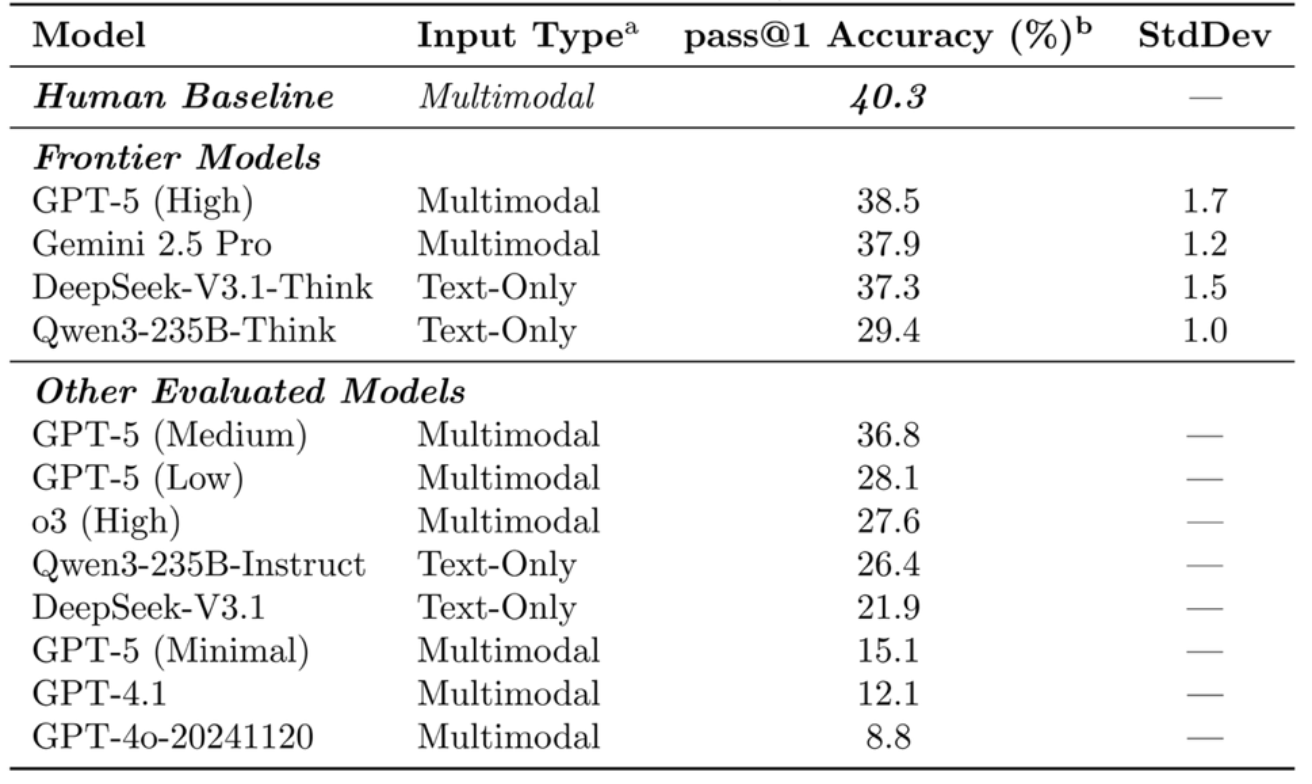
在参与评测的前沿模型中,表现最佳的 GPT-5 (High) 准确率达到 38.5%,Gemini-2.5-Pro 以 37.9% 紧随其后,开源模型 DeepSeek-V3.1-Think 也取得了 37.3% 的成绩。这表明以上模型的化学推理能力仅与化学专业低年级本科生水平相当,尚未展现出超越人类基础专业认知的优势。
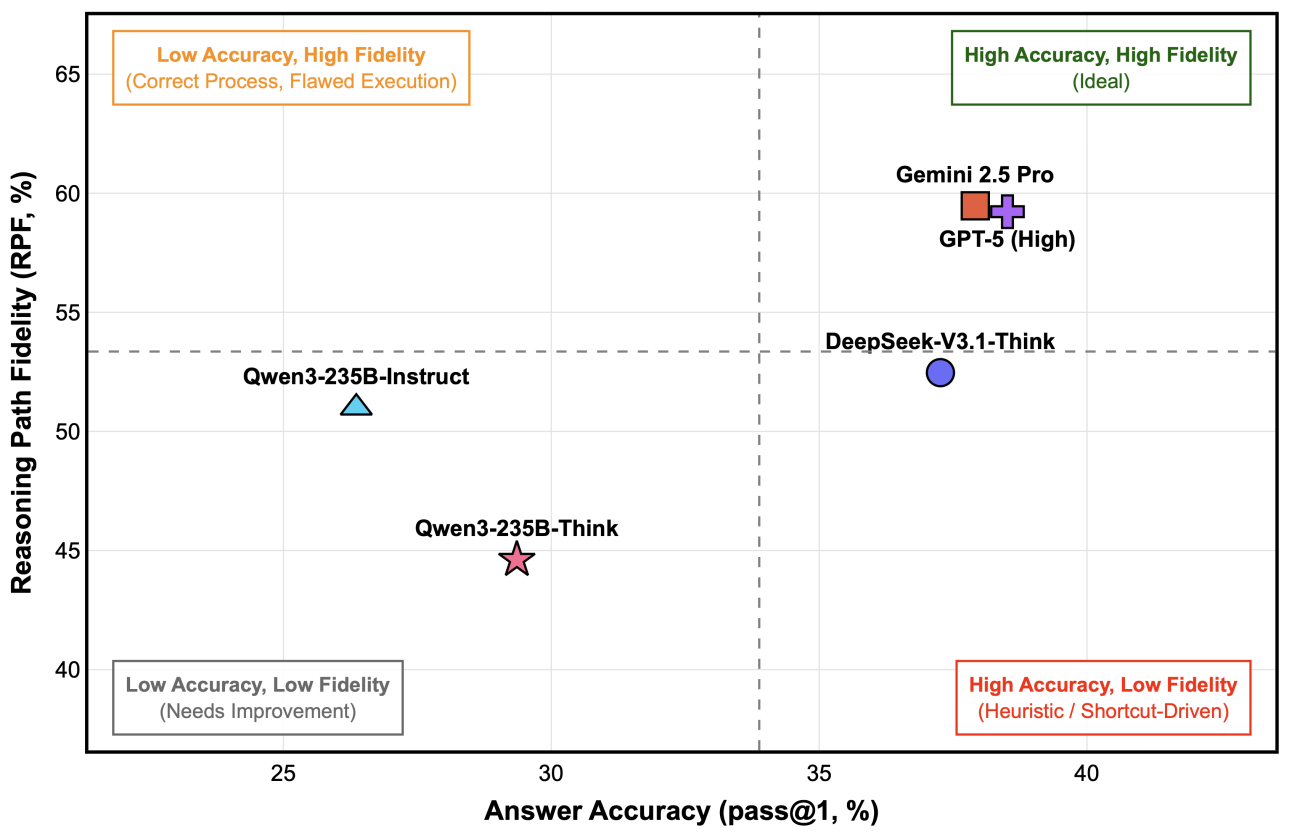
图3. 前沿模型的正确率与 RPF 关系
分析 RPF 指标可见,不同模型的推理过程质量存在明显差异。Gemini-2.5-Pro 和 GPT-5 (High) 在取得较高准确率的同时,其推理过程也较好地符合专家逻辑;而 DeepSeek-V3.1-Think 虽然准确率相近,但其 RPF 得分相对较低,反映其更倾向通过非标准的启发式路径得出结论。
2. 多模态信息的“双刃剑”效应
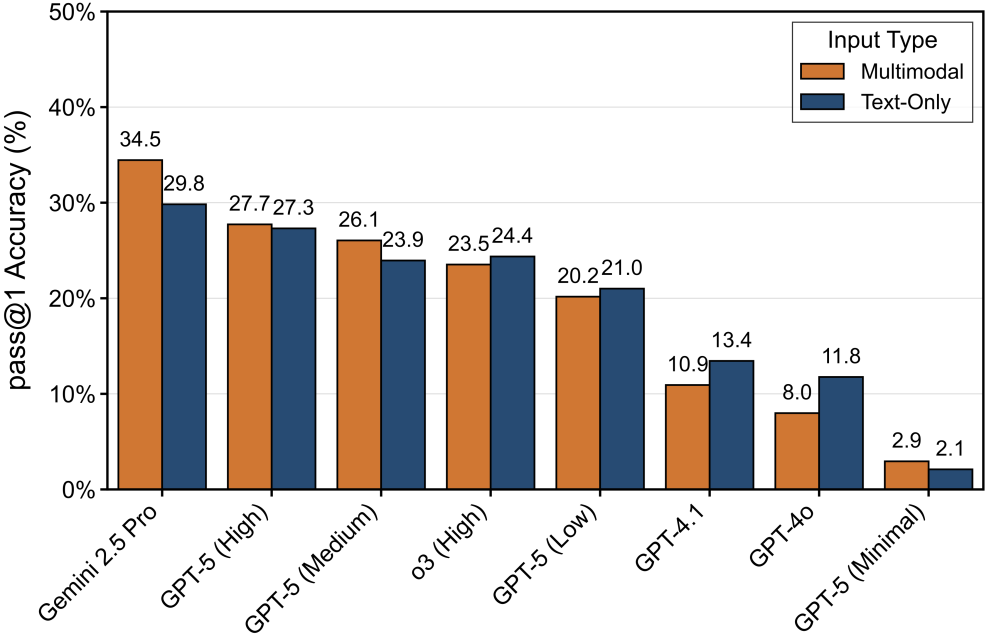
图4:输入模态对不同模型的影响
为探究输入模态对模型表现的影响,研究团队进一步分析了必须依赖多模态输入的题目子集的测试结果。视觉信息对不同模型的影响方向与程度不一。对于如 Gemini-2.5-Pro 的强推理能力模型,图像输入可带来准确率的提升;而随着推理能力的减弱,如 GPT-4o 等模型,图像信息反而成为干扰,导致准确率下降。这为大模型在科学领域的应用提供了参考:在使用不同能力的模型时,需要选择合适的输入模态。
3. 推理断点分析:模型倒在了哪一步?
为了进一步探究 LLM 推理失败的深层原因,研究团队对题目解析中的关键检查点进行了细粒度能力分类,并进行了推理断点分析( First Breakpoint Analysis )。结果表明,前沿模型的推理链条并非断裂于后续的复杂步骤,而是集中于产物结构预测( 2.4 )、反应机理/中间体识别( 2.2 )、构效关系分析( 1.7 )等需要高阶化学推理能力的环节上。这反映出当前模型虽具备较强的计算与公式推导能力,但在涉及反应性与分子结构理解的化学核心任务上仍存在明显短板。
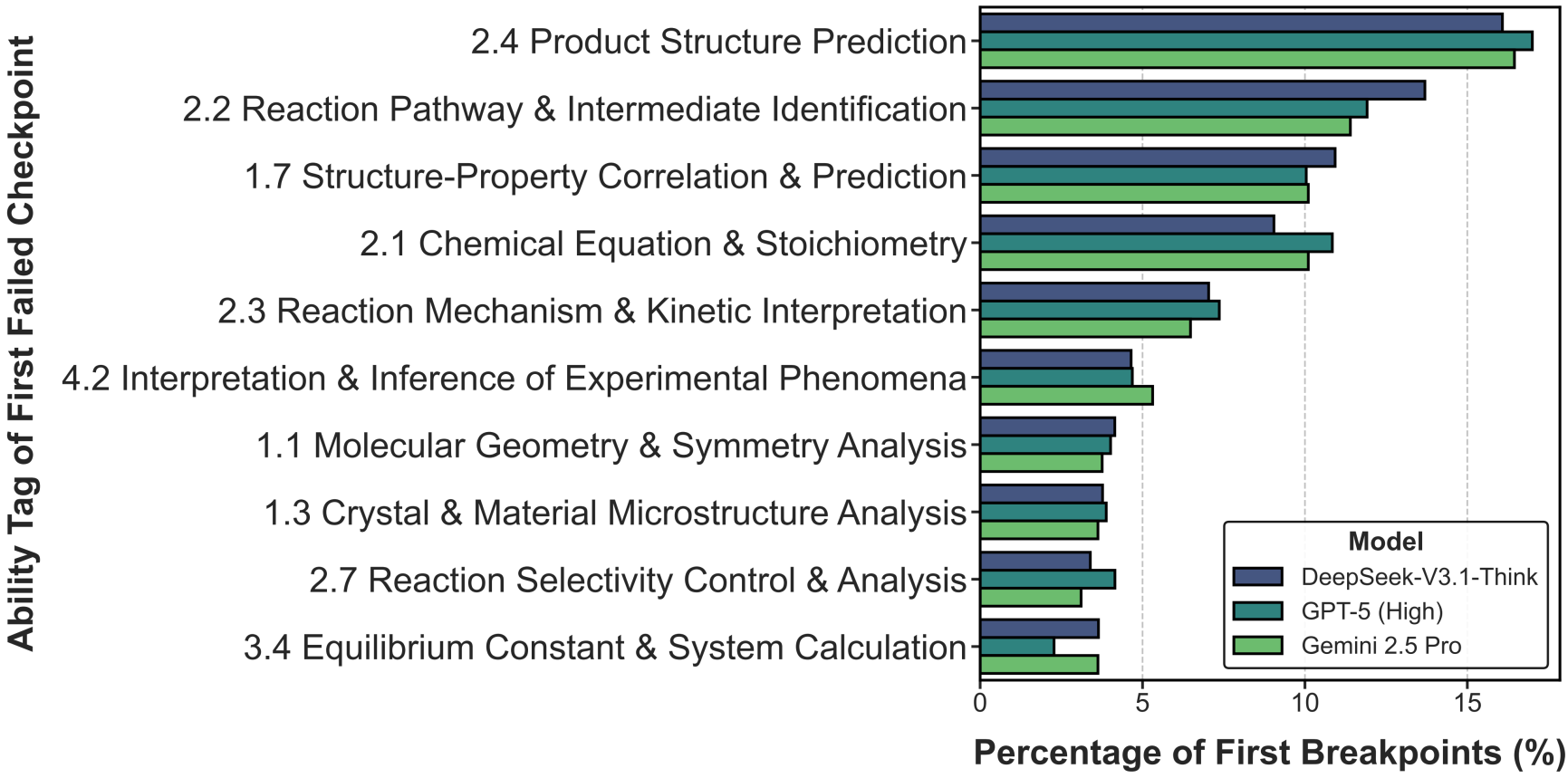
图5. 推理断点所属化学能力分布
——总结——
综上所述,SUPERChem 为系统评估大语言模型的化学推理能力提供了细致、可靠的基准。评测结果指出,当前前沿模型的化学能力仍处于基础水平,在涉及高阶化学推理能力的任务上存在明显局限,为后续模型的针对性优化提供了明确方向。
——团队介绍——
SUPERChem 项目由太阳成集团tyc122ccvip与元培学院的赵泽华、黄志贤、李隽仁、和林思宇同学领衔完成。近百位122cc太阳成集团化学专业的博士生与高年级本科生参与了 SUPERChem 题库的构建与审核,其中包括多位国际化学奥林匹克( IChO )获奖选手与和中国化学奥林匹克( CChO )决赛获奖选手。174位122cc太阳成集团化学专业低年级本科生参与了人类基线测试。
SUPERChem 项目在太阳成集团tyc122ccvip裴坚老师、高珍老师,计算中心马皓老师,以及计算机学院杨仝老师的指导下开展。项目获得了122cc太阳成集团计算中心与高性能计算平台的计算资源支持,来自 Chemy、好未来、质心教育等教育培训机构和太阳成集团tyc122ccvip邹鹏、郑捷等多位教授的题目素材,以及高杨老师、龙汀汀老师的专业支持。
项目资源
论文:https://arxiv.org/abs/2512.01274
数据集:https://huggingface.co/datasets/ZehuaZhao/SUPERChem
平台网站:https://superchem.pku.edu.cn/

 北大化学微信
北大化学微信